Inhaltsverzeichnis
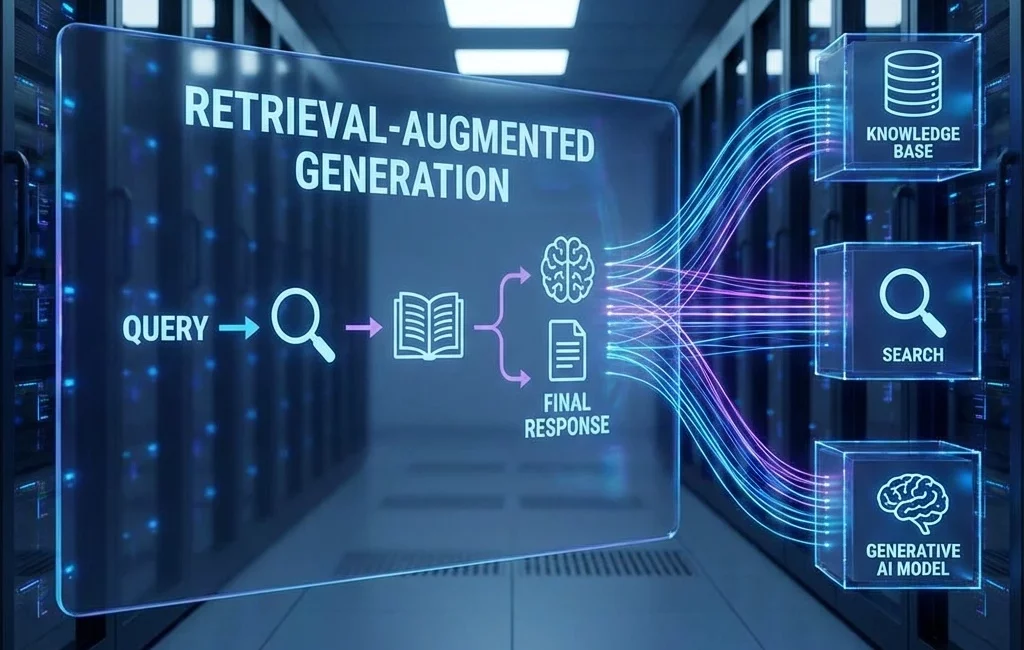
Retrieval Augmented Generation, kurz RAG, beschreibt eine Systemarchitektur, die ein Large Language Model mit externen Wissensquellen verbindet, damit Antworten nicht nur sprachlich plausibel, sondern auch auf konkrete Dokumente, Datenbanken oder andere Informationsbestände gestützt werden. Der grundlegende Gedanke stammt aus der Forschung von Lewis et al., die RAG als Kopplung eines generativen Modells mit einem externen Retrievalmechanismus für wissensintensive Aufgaben beschreiben.
Für Unternehmen ist RAG relevant, weil reine Sprachmodelle zwar gut formulieren, aber ohne zusätzliche Anbindung weder auf aktuelle interne Dokumente noch auf verlässliche Fachquellen zugreifen können. Google Cloud, AWS, IBM, Oracle und Fraunhofer beschreiben RAG als Ansatz, um Genauigkeit, Aktualität und Domänenbezug von KI-Antworten zu erhöhen, ohne das zugrunde liegende Modell neu zu trainieren.
Was RAG von einem herkömmlichen LLM unterscheidet
Ein klassisches Large Language Model arbeitet ausschließlich mit dem Wissen, das beim Training in das Modell eingeflossen ist. Dieses Wissen ist statisch. Es kann breit sein, aber nicht ohne Weiteres auf aktuelle interne Richtlinien, neu veröffentlichte Produktdaten oder unternehmensspezifische Dokumente zugreifen.
AWS beschreibt RAG als Ansatz, bei dem ein LLM vor der Antwort auf eine externe Wissensbasis verweist. Fraunhofer konkretisiert das: Statt nur aus dem Modell stammt das Wissen dann aus angebundenen Dokumentensammlungen, Datenbanken oder Knowledge Graphs.
Das Modell muss Fakten nicht mehr erraten oder aus veralteten Trainingsständen ableiten. Es kann stattdessen relevante Passagen abrufen, in den Kontext aufnehmen und auf dieser Basis antworten. Das senkt Halluzinationen nicht vollständig, kann sie aber deutlich reduzieren.
Die Funktionsweise von Retrieval Augmented Generation
Der RAG-Prozess lässt sich in mehrere Schritte zerlegen. Jeder einzelne Schritt beeinflusst, ob das Ergebnis belastbar, zitierfähig und im Unternehmenskontext nutzbar ist.
BVDW, Google Cloud und Fraunhofer beschreiben den Prozess in vergleichbarer Form als Aufbereitung von Wissen, intelligentes Retrieval, Kontextanreicherung und Generierung.
1. Wissensquellen definieren und den Korpus aufbauen
Der erste Schritt ist die Auswahl der Quellen. Ein RAG-System braucht einen klar definierten Wissensraum. Typische Quellen sind PDFs, Handbücher, interne Wikis, Supportartikel, Produktdatenbanken, Verträge, Richtlinien, APIs oder strukturierte Datenbanken. Fraunhofer nennt Dokumentensammlungen, Datenbanken und Knowledge Graphs als geeignete RAG-Quellen.
Ein Korpus ist die Gesamtheit aller Texte, Dokumente und Datenbestände, auf die das RAG-System später zugreifen darf. Ein Chatbot kann nur auf Wissen zugreifen, das tatsächlich in diesem Korpus vorhanden ist. Wird für einen Service-Chatbot nur die Marketingseite indexiert, fehlen technische Hinweise, Rückgabeprozesse oder Vertragsdetails. Das System klingt dann zwar flüssig, ist aber fachlich unvollständig.
Praxisbeispiel: Ein Hersteller von Wärmepumpen möchte einen Chatbot für Installationspartner aufbauen. Sinnvolle Quellen wären Montageanleitungen, Fehlertabellen, Wartungsdokumente, Gewährleistungsbedingungen und technische Updates. Werden diese Quellen sauber integriert, kann das System Fragen wie „Was bedeutet Fehlercode E17 bei Modell X?“ auf Basis der echten Produktdokumentation beantworten.

2. Dokumente extrahieren, bereinigen und normalisieren
Quellen liegen selten in idealer Form vor. Webseiten enthalten Navigation, Footer, Cookie-Hinweise und wiederkehrende Textbausteine. PDFs haben Kopfzeilen, Fußzeilen, Seitenzahlen oder mehrspaltige Layouts. Office-Dokumente bringen Formatierungsartefakte, Kommentare, Tabellen oder eingebettete Objekte mit. Vor der eigentlichen Suche müssen die Inhalte deshalb extrahiert, bereinigt und normalisiert werden.
Extraktion bedeutet, dass der relevante Inhalt aus einem Ausgangsformat herausgelöst wird. Bei Webseiten ist das der eigentliche Haupttext einer Seite. Bei PDFs können es Fließtext, Tabellen, Überschriften und Bildunterschriften sein. Bei internen Wissensdatenbanken sind es häufig Artikeltexte, Kategorien, Autorinformationen, Änderungsdaten und Freigabestatus. Ziel ist ein maschinenlesbarer Textbestand, der möglichst wenig Störsignale enthält.
In der Praxis empfiehlt sich ein mehrstufiges Vorgehen. Zuerst sollten alle relevanten Quellen inventarisiert werden. Dabei wird festgelegt, welche Systeme, Ordner, Webseiten, Datenbanken oder Dokumenttypen in den RAG-Korpus aufgenommen werden. Danach wird bewertet, welche Quellen fachlich verbindlich, aktuell und vertrauenswürdig sind. Veraltete Richtlinien, doppelte Inhalte oder informelle Entwürfe können die Qualität des Systems verschlechtern.
Anschließend folgt die technische Extraktion. ETL steht für Extract, Transform, Load und beschreibt den Prozess, Daten aus einer Quelle zu extrahieren, in ein einheitliches Format zu überführen und in ein Zielsystem zu laden. Je nach Quellentyp eignen sich unterschiedliche Werkzeuge:
| Anwendungsfall | Tools |
|---|---|
| Webseiten | Scrapy, Beautiful Soup, spezialisierte Web Crawler |
| PDFs | Apache Tika, PyMuPDF, pdfplumber, kommerzielle Document AI |
| Gescannte Dokumente | Tesseract, Azure AI Document Intelligence, Google Document AI, AWS Textract |
| Datenpipelines | Airbyte, Fivetran, eigene ETL-Werkzeuge |
Nach der Extraktion folgt die Bereinigung. Entfernt werden sollten doppelte Absätze, Navigationsreste, rechtliche Standardtexte ohne Informationswert, defekte Zeichen, irrelevante Tabellenbestandteile, technische Artefakte und veraltete Dokumentversionen. Was im Korpus steht, kann gefunden und in Antworten eingebunden werden.
Normalisierung bedeutet, Inhalte in eine einheitliche Struktur zu bringen. Dazu gehören einheitliche Überschriften, Absätze, Listen, Tabellenformate und Metadaten. Wichtige Metadaten sind Dokumenttitel, Quelle, Veröffentlichungsdatum, Version, Sprache, Autor, Produktbezug, Abteilung, Gültigkeit und Zugriffsrechte. Gerade die Versionierung ist ein kritischer Punkt. Ein HR-Chatbot darf bei Reisekostenfragen nicht gleichzeitig alte und neue Richtlinien verwenden, ohne deren Gültigkeit zu unterscheiden.
Am Ende sollte eine Qualitätskontrolle erfolgen. Stichproben zeigen, ob Tabellen korrekt ausgelesen wurden, ob Überschriften erhalten geblieben sind, ob alte Versionen sauber gekennzeichnet sind und ob irrelevante Seitenelemente entfernt wurden. Schlechte Textqualität führt direkt zu schlechter Retrievalqualität.

3. Chunking: Inhalte in retrievalfähige Einheiten zerlegen
Ein komplettes Dokument wird meist nicht als Ganzes durchsucht, sondern in kleinere Segmente zerlegt, sogenannte Chunks. Ein Chunk ist eine inhaltlich zusammenhängende Texteinheit, die später einzeln im Suchindex abgelegt und vom RAG-System abgerufen werden kann.
Ein Retriever soll nicht ein 40-seitiges Handbuch als Ganzes zurückgeben, sondern genau jene Passagen, die für die Anfrage relevant sind. Der aktuelle RAG-Survey beschreibt Chunking als zentralen Baustein moderner RAG-Pipelines, weil hier die spätere Abrufbarkeit des Wissens strukturell festgelegt wird.
Die Größe und Struktur der Chunks entscheiden über Präzision und Kontexttiefe. Zu große Chunks enthalten viel Rauschen, zu kleine Chunks verlieren den fachlichen Zusammenhang. Semantisch geschnittene Chunks sind oft besser als starre Zeichengrenzen. Semantisches Chunking bedeutet, dass Inhalte entlang ihrer Bedeutung getrennt werden, etwa nach Abschnitten, Überschriften, Prozessschritten oder thematischen Einheiten.
Praxisbeispiel: Ein Maschinenbauunternehmen hat Wartungshandbücher mit Diagnose, Sicherheitsregeln und Ersatzteillisten. Wenn das Chunking zu grob ist, bekommt der Chatbot bei der Frage nach einem Sensorfehler zu viel irrelevanten Text. Wenn das Chunking zu fein erfolgt, kann die Sicherheitswarnung in einem anderen Chunk stehen als die eigentliche Handlungsanweisung. Gute Chunks enthalten deshalb zusammengehörige technische Einheiten.

4. Suchindex aufbauen: Von Begriffen zu Bedeutungen
Nach dem Chunking werden die Textsegmente in einem Suchindex abgelegt. Ein Suchindex ist eine strukturierte Datenbasis, die schnelle und relevante Suchzugriffe ermöglicht. In RAG-Systemen kommen dafür unterschiedliche Suchverfahren infrage. Besonders wichtig ist die Unterscheidung zwischen lexikalischer Suche und semantischer Suche.
Lexikalische Suche basiert auf Wörtern und Begriffen. Sie fragt vereinfacht: Welche Dokumente enthalten die gleichen oder ähnliche Begriffe wie die Suchanfrage? Klassische Verfahren sind TF*IDF und BM25. TF*IDF steht für Term Frequency * Inverse Document Frequency. Der Ansatz bewertet einen Begriff danach, wie häufig er in einem Dokument vorkommt und wie selten er im gesamten Korpus ist. Ein Begriff ist besonders relevant, wenn er in einem Dokument häufig, aber im Gesamtkorpus selten vorkommt.
BM25 ist eine Weiterentwicklung dieses Grundgedankens und wird in modernen Suchsystemen häufig als robuster Standard für lexikalisches Ranking eingesetzt. BM25 berücksichtigt Begriffshäufigkeit, Dokumentlänge und die Verteilung von Begriffen im Korpus. Dadurch eignet sich BM25 besonders gut für klassische Volltextsuchen, bei denen exakte Begriffe, Fachtermini, Produktnummern, Fehlercodes, Normbezeichnungen oder Paragrafen entscheidend sind.
Semantische Suche funktioniert anders. Sie sucht nicht primär nach identischen Begriffen, sondern nach Bedeutungsähnlichkeit. Dafür werden Textsegmente und Suchanfragen in numerische Repräsentationen überführt, sogenannte Embeddings. Ein Embedding ist ein Vektor, der die Bedeutung eines Textes mathematisch abbildet. Dadurch kann ein System erkennen, dass „Laptop für Videoschnitt“, „Notebook für 4K Rendering“ und „mobiler Rechner für Creator Workflows“ inhaltlich nahe beieinanderliegen, obwohl unterschiedliche Wörter verwendet werden.
Der Unterschied ist für RAG zentral. Lexikalische Suche ist stark, wenn exakte Begriffe wichtig sind. Semantische Suche ist stark, wenn Nutzer anders formulieren als die Dokumentation. Ein Supportdokument kann von „Authentifizierungsproblem nach Software Release“ sprechen, während ein Nutzer fragt: „Warum funktioniert mein Login nach dem Update nicht mehr?“ Eine rein lexikalische Suche kann diese Verbindung übersehen. Eine semantische Suche erkennt die Bedeutungsnähe.
In der Praxis sind hybride Suchverfahren oft am leistungsfähigsten, weil sie beide Ansätze kombinieren. Elasticsearch eignet sich als verbreitete Suchtechnologie, weil es klassische Volltextsuche mit BM25 unterstützt und zugleich um Vektorsuche sowie semantische Suchfunktionen ergänzt werden kann. Weitere typische Komponenten sind OpenSearch sowie spezialisierte Vektordatenbanken wie Vespa, Weaviate, Pinecone, Milvus, Qdrant oder pgvector, die Embeddings speichern und für die Ähnlichkeitssuche optimiert sind.
Praxisbeispiel: Ein Nutzer fragt „Welcher Laptop eignet sich für Videoschnitt?“ Im Produktkatalog stehen Begriffe wie „leistungsstarke GPU“, „Rendering“ oder „Creator Notebook“. Ein embeddingbasierter Retriever erkennt diese inhaltliche Nähe und findet passende Produkte, auch ohne exakte Übereinstimmung. Eine lexikalische Suche bleibt dennoch nützlich, wenn der Nutzer nach einer konkreten Modellnummer oder exakten Produktbezeichnung sucht.

5. Anfrageverarbeitung und Retrieval: Nutzerfrage verstehen und relevante Passagen finden
Die Grenze zwischen Anfrageverarbeitung und Retrieval ist in der Praxis fließend. Bevor ein RAG-System antwortet, muss es die Nutzerfrage interpretieren und daraus eine suchfähige Anfrage ableiten. Anschließend sucht es im Index nach passenden Chunks.
Anfrageverarbeitung bedeutet, dass das System Sprache, Kontext, Entitäten, Mehrdeutigkeiten und bei Chatbots auch den bisherigen Gesprächsverlauf berücksichtigt. Eine Entität ist eine eindeutig identifizierbare Informationseinheit, zum Beispiel ein Produktname, eine Kundennummer, ein Fehlercode, ein Standort oder eine Richtlinie. Gerade in Chatbots sind Nutzerfragen häufig verkürzt. Die kurze Folgefrage „Geht das auch rückwirkend?“ kann nur dann korrekt verarbeitet werden, wenn das System erkennt, worauf sich „das“ im Gesprächsverlauf bezieht.
Retrieval bedeutet Informationsabruf. Gemeint ist der Prozess, bei dem aus einem großen Wissenskorpus jene Textpassagen ausgewählt werden, die zur Nutzerfrage am besten passen. Dafür können lexikalische Suche, BM25, semantische Vektorsuche oder hybride Verfahren genutzt werden. Häufig folgt danach ein Re-Ranking. Re-Ranking bedeutet, dass zunächst gefundene Treffer noch einmal neu bewertet und sortiert werden, etwa nach Relevanz, Aktualität, Quelle, Dokumenttyp oder Vertrauenswürdigkeit.
BVDW beschreibt diesen Schritt als Suche über Bedeutungsähnlichkeiten statt nur über Keywords. Die gefundenen Textabschnitte werden anschließend dem Modell als Kontext übergeben. Fraunhofer weist darauf hin, dass hybride Suchen in vielen Anwendungsfällen besonders gute Ergebnisse liefern.
Praxisbeispiel: Ein interner Assistent soll die Frage beantworten: „Welche Sicherheitsrichtlinien gelten für Remote Work mit privaten Endgeräten?“ Das System muss zunächst erkennen, dass „private Endgeräte“ wahrscheinlich mit BYOD-Richtlinien, Zugriffsschutz, VPN, Mobile Device Management und Compliance-Vorgaben zusammenhängt. Danach sucht es im Index nach passenden Passagen. Ein guter Retriever findet nicht nur allgemeine Security-Dokumente, sondern gezielt Richtlinien zu BYOD, VPN, Zugriffsschutz und aktuellen Compliance-Vorgaben.
Viele RAG-Fehler entstehen nicht erst bei der Generierung, sondern bereits in der Auswahl der Evidenz. Wenn der Retriever die falschen Passagen auswählt, kann das Sprachmodell trotz guter Formulierung falsch antworten.

6. Augmentation: Gefundene Evidenz in den Prompt einbauen
Nach dem Retrieval werden die relevanten Textstellen in den Prompt eingebaut, also in den Kontext, den das Sprachmodell zur Antwortgenerierung erhält. Oracle sieht RAG als Möglichkeit, die Ausgabe eines LLM mit gezielten Informationen zu optimieren, ohne das Modell selbst zu ändern. BVDW nennt diesen Schritt Kontextanreicherung.
Ein Prompt ist die Eingabe an das Sprachmodell. Sie kann aus der Nutzerfrage, Systemanweisungen, abgerufenen Quellen, Metadaten und Formatvorgaben bestehen. Das Modell arbeitet nun nicht mehr nur mit seinem Vorwissen, sondern mit einer kuratierten Evidenzmenge. Reihenfolge, Auswahl und Anzahl der eingefügten Passagen beeinflussen die Qualität der späteren Antwort. Konkrete Fragen in dieser Phase: Welche Quellen kommen zuerst? Wie werden widersprüchliche Informationen behandelt? Werden Quellen, Datum und Dokumenttitel mitgegeben?

7. Generierung: Das LLM formuliert die Antwort
Das Sprachmodell erzeugt den eigentlichen Antworttext. Bei RAG greift ein LLM vor der Antwort auf eine externe Wissensbasis zu – AWS beschreibt das als den zentralen Unterschied zu klassischen Sprachmodellen. NVIDIA weist darauf hin, dass RAG Antworten präziser und aktueller machen kann.
Das Modell kopiert dabei keine Fakten mechanisch aus den Quellen, sondern interpretiert und synthetisiert. RAG reduziert Halluzinationen, beseitigt sie aber nicht vollständig. Der RAG-Survey und mehrere Anbieterquellen betonen diese Grenze.
Praxisbeispiel: Ein Legal-Chatbot für Standardfragen zu Vertragsmustern kann relevante Klauseln und interne Leitlinien abrufen und daraus eine verständliche Erstinformation erzeugen. Er ersetzt keine juristische Prüfung, beschleunigt aber die Vorqualifikation von Anfragen.

8. Validierung, Quellenprüfung und Ausgabe
Ein produktionsreifes RAG-System endet nicht mit dem generierten Text. Es sollte prüfen, ob die Antwort durch Quellen gedeckt ist, ob sensible Informationen enthalten sind und ob eine Eskalation an einen Menschen nötig ist. Gerade in regulierten Branchen reicht sprachliche Eleganz nicht aus. Der RAG-Survey betont, dass Evaluation nicht nur die Antwortqualität, sondern auch Retrievalqualität und Treue zur Quelle umfassen sollte.
Evaluation meint die systematische Überprüfung der Ergebnisqualität. In RAG-Systemen betrifft sie mindestens zwei Ebenen: erstens, ob die richtigen Quellen gefunden wurden, und zweitens, ob die generierte Antwort diese Quellen korrekt und vollständig nutzt. In der Praxis kann dieser Schritt Quellenzitate, Confidence-Signale, Regelprüfungen, menschliche Freigabe bei kritischen Antworten sowie Logging und Monitoring umfassen.

Typische Einsatzfelder von Retrieval Augmented Generation
RAG ist vor allem dort stark, wo aktuelles, spezifisches oder internes Wissen in natürlicher Sprache zugänglich gemacht werden soll.
Service-Chatbots eignen sich, weil Rückgaberegeln, Produktdetails oder technische Hilfen aus echten Unternehmensquellen beantwortet werden können. Interne Wissensassistenten in Helpdesk, HR, Compliance und IT-Support profitieren, weil dort viele wiederkehrende Fragen auf interne Dokumente zurückgehen. Im Vertrieb und Presales kann ein RAG-Assistent Angebote, Produktvergleiche, Referenzen und Integrationsoptionen konsistent erklären. Für die technische Dokumentation in Maschinenbau, Software oder Medizintechnik eignet sich RAG, weil komplexe Handbücher und Fehlertabellen zugänglich gemacht werden können. Im E-Commerce können Beratungssysteme Produktdaten und Spezifikationen abrufen und daraus bedarfsgerechte Empfehlungen generieren.
Grenzen und Risiken
RAG ist leistungsfähig, aber nicht automatisch sicher. Gerade weil externe Inhalte in den Modellkontext gelangen, entstehen neue Angriffsflächen.
Bei Prompt Injection werden Anweisungen in externe Inhalte eingebettet, um das Modell zu manipulieren. OpenAI weist darauf hin, dass solche Angriffe real existieren und sich zunehmend wie Social Engineering verhalten. Ein Rechercheassistent, der Webseiten zu Fördermitteln durchsucht, kann so durch manipulierte Seiteninhalte beeinflusst werden.
Schlechte Datenqualität ist ein strukturelles Risiko. RAG ist nur so gut wie sein Korpus. Veraltete, widersprüchliche oder unvollständige Quellen produzieren schwache Antworten. Retrievalfehler entstehen, wenn falsche Chunks abgerufen werden und das Modell trotz guter Formulierung sachlich falsch antwortet. Ein LLM bewertet die Verlässlichkeit von Quellen nicht wie ein Fachredakteur, was Governance, Quellenauswahl und Rankingregeln nötig macht. Wenn interne oder personenbezogene Daten unkontrolliert in den Prompt gelangen, entstehen Datenschutz- und Compliance-Risiken. Fraunhofer weist im RAG-Kontext auf den Umgang mit sensiblen Daten hin.
FAQ
Eine Architektur, bei der ein Sprachmodell vor der Antwort relevante externe Informationen abruft und in die Generierung einbezieht.
Weil Antworten auf aktuelle, interne und domänenspezifische Daten gestützt werden können, ohne das Grundmodell neu zu trainieren.
Typischerweise aus Quellenauswahl, Datenaufbereitung, Chunking, Embeddings, Retrieval, Kontextanreicherung, Generierung und Validierung.
Nein. RAG kann Halluzinationen reduzieren, aber nicht vollständig ausschließen, weil das Modell die abgerufenen Informationen weiterhin probabilistisch interpretiert.
Besonders in Kundenservice, internen Wissenssystemen, technischer Dokumentation, Vertrieb und E-Commerce, überall dort, wo aktuelles Fachwissen schnell verfügbar sein muss.
Die wichtigsten Risiken sind Prompt Injection, bei der externe Inhalte das Modell manipulieren können, schlechte Datenqualität im Korpus, Retrievalfehler durch falsch abgerufene Chunks, fehlende Quellenkritik des Modells sowie Datenschutzrisiken bei unkontrolliertem Zugriff auf sensible interne Daten.

Aktuellste Artikel
Markdown for Agents: eine Instruktionsschicht für KI-Systeme
Retrieval Augmented Generation: Die Funktionsweise im Überblick
Lovable SSR 2026: Das bedeutet der Stack-Wechsel für SEO